Practitioners guide to fine-tune LLMs for domain-specific use case
with Aditya Khandekar CorridorPlatforms

Large Language Models (LLMs) have emerged as a significant force in the family of Generative AI, capturing the imagination of vast possibilities. With the launch of ChatGPT, organizations, and companies are increasingly embracing these sophisticated models in existing analytical pipelines as well as spawning new use cases which were not easily possible prior to LLMs. However, while the allure of Generative AI may be captivating, it is crucial to recognize that deploying LLMs in production can carry substantial risks and implications if the models don’t work as intended. Several reasons for this…and in this three-part blog series, we shall dive into our experience of fine-tuning and employing LLMs for a domain-specific use case. Our journey will encompass defining the problem statement, outlining the analytical pipeline, and drawing key conclusions from our experiments to assess model performance and tackle hallucination risks. We will also share best practices along the way.
The three-part series is laid down like this
- Defining the Problem Statement and our Analytical Pipeline.
- Key Learnings and Conclusions: Addressing Model Performance and Hallucination Risks.
- How the performance of a decoder-only LLM differs from encoder-only (BERT) and encoder-decoder (Flan T5) based LLMs for the same task?
Defining our problem statement and dataset
The problem statement is defined as follows, given some consumer complaints in the form of text, we need to classify those complaints into five potential classes
- credit reporting
- debt collection
- mortgages and loans
- credit cards
- retail banking
The source of the dataset is Kaggle. Hence we can define this problem as a text classification problem. In the broader analytical pipeline, the text classification of the interaction between the customer and the agent will result in a problem code which along with other customer data (# of accounts, balances, tenure, etc.) will be used in a decision engine to execute an action to solve the customer’s issue. Below is a sample of our dataset.

The dataset was also class imbalanced and contained some impurities. However, we intentionally did not preprocess the dataset much. Our main intention was to see how Large Language Models would perform if fine-tuned on less preprocessed datasets. So in our initial rounds of preprocessing, we removed null values and took out a sample of our dataset.
Choosing the correct foundation model
Foundation Models (in the context of language modeling) are defined as pre-trained Large Language Models, trained on huge amounts of data for multiple tasks. It represents the ‘starting point’ of modern language modeling. From here we can either fine-tune a model, add prompts, add a knowledge base, and can do a lot of things, but it all starts with a Foundation Model. Note, FMs are not all created equal. Some of them could be domain-specific (ex: BloombergGPT by Bloomberg). Even Foundation models trained on similar datasets can also vary in their responses. Some examples include:
- The response from Llama 7B will be different from Llama 7B chat (instruction tuned)
- The response of Falcon 7B and Llama 7B might be different in different scenarios
- The response of Falcon will be completely different from the responses by BloombergGPT.
In our use case, choosing a model with better natural language understanding capability and size was important. As more LLMs are created in the marketplace, a wide diaspora of them will be available for vertical, choosing the right one is VERY critical for the success of the use case. Falcon was quite popular when we started. Hence we choose Falcon 7B for our fine-tuning process. Falcon is a family of LLMs built by the Technology Innovation Institute. These models were similar to LLaMA models when compared with the standard benchmarks.
Why not just use prompts and LangChain for the process?
That is an awesome question. We started our process by crafting prompts and expecting some results from the raw foundation models. However, the results were not close to the correct answers. The below table shows the generated text from a Falcon 7B model with prompts.

Further in-depth analysis and insights on, what was the prompt given to these models and different results from Falcon 7B and Falcon 7B instruct will be reflected in the second part of the blog.
So one key insight for us was that in most enterprise LLM-based use cases, ‘variance of outcome’ will always be an issue, and to get industrial-level performance that balances risk and benefit, you most probably will need to fine-tune the weights of the underlying foundation model to get a production-grade system.
Fine-tuning LLMs
For a general text classification task, a popular architecture to use is a Transformer based text encoder model to get the vector of embedding followed by a neural net (optional) and finally a supervised classifier for output classification. The below image shows how we can fine-tune a BERT model (encoder—only model) for the text classification task.
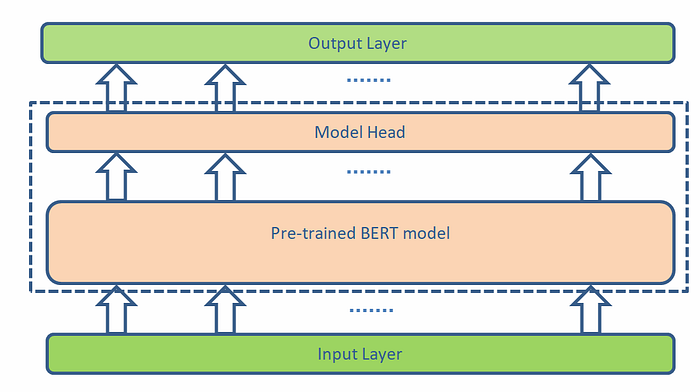
This architecture is powerful and we will talk more about this in the third part of our blog series. So stay tuned for that.
But, in the case of LLMs, the same fine-tuning methodology like BERT might not work for two main reasons
- The number of parameters for a foundation model can be very large (models like LLaMA or Falcon have model parameters ranging from 7B to 70B). Hence fine-tuning them with traditional transfer learning approaches can be very compute-intensive.
- You also run the risk of ‘catastrophic forgetting’ where the foundation model loses its underlying memory while retraining
Hence we try a better, optimized, and parameter-efficient fine-tuning technique like LoRA (Low-Rank Adaptation). LoRA offers a parameter-efficient alternative to traditional fine-tuning methods for LLMs like LLaMA or Falcon.
LoRA tackles this challenge of large computation by employing a low-rank transformation technique, similar to PCA and SVD, to approximate the weight matrices of the model with lower-dimensional representations. This approach allows us to decompose the weight changes during fine-tuning into smaller matrices, significantly reducing the number of parameters that need to be updated. As a result, LoRA can efficiently adapt the model to a target domain and task without incurring excessive computational costs.
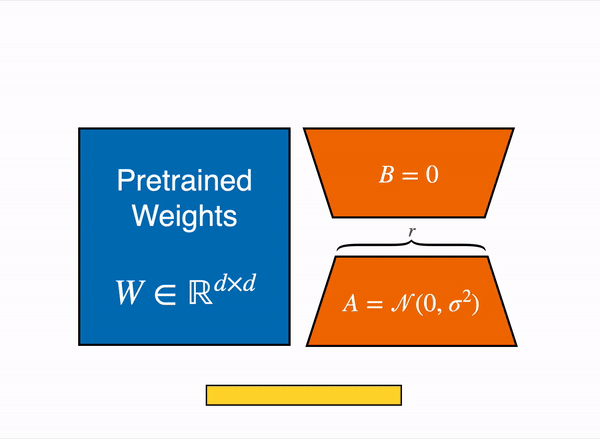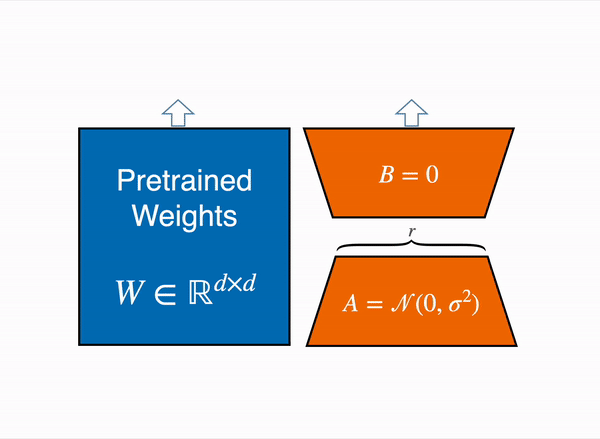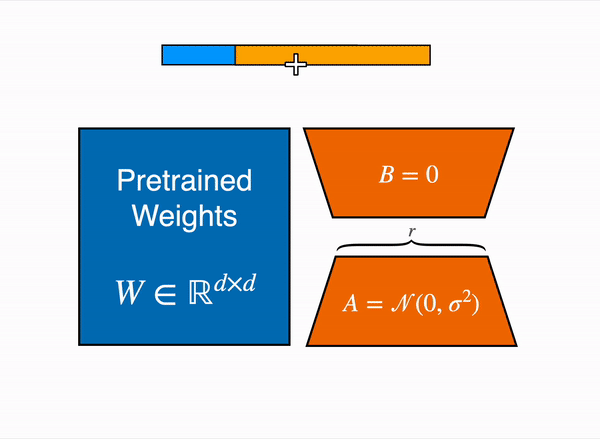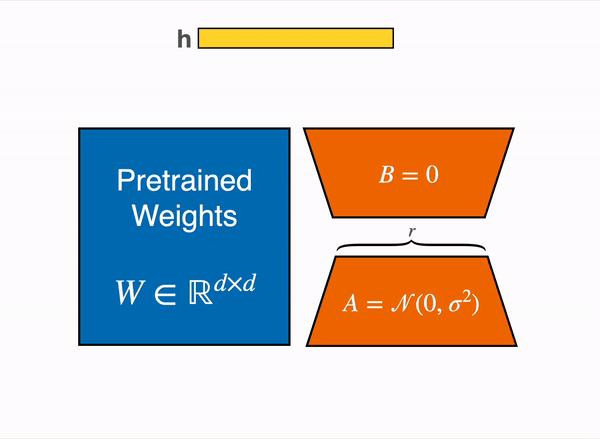
To get a better intuition, imagine you have a weight matrix W which has a dimension of 768 x 768 . Now we can decompose the matrix into two matrix W_A and W_B such that W_A (768 x r) and W_B (r x 768) , Now we can define our matrix W as W = W_A @ W_B (Where @ is matrix multiplication). So initially the number of trainable parameters of W was 768 * 768 = 589824 whereas now the total number of trainable parameters of W as decomposition of W_A and W_B becomes 768 × 8) + (8 × 768) = 12288 which is a reduction of parameters by 97 %. Here is a pseudo code to understand this more
# inspired from the blog by Sebastian Raschka
# https://sebastianraschka.com/blog/2023/llm-finetuning-lora.html
import torch
import torch.nn as nn
# define the input and the output dimension of the neural network
# to define the size of the weight metrix
# let's assume the size of our weight matrix becomes W of dimension (768 x 768)
# the total number of parameters in W is 768 * 768 = 589824
input_dim = 768
output_dim = 768
W = ... # weight of my neural network
# the rank 'r' is for the low rank adaptation
# we can represent our weight W as product of two matrix W_A and W_B such that
# W (768 x 768) = W_A (768 x r) @ (r x 768)
# the total number of parameters we have now is (768 × 8) + (8 × 768) = 12288
# hence we define our W_A and W_B with r = 8
rank = 8
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA weight A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA weight B
# this is how my regular feed neural net model with weights W look like
def regular_forward_matmul(x, W):
h = x @ W
return h
# and this is how my feed forward with LoRA looks like
def lora_forward_matmul(x, W, W_A, W_B):
# regular matrix multiplication
# where W is NOT trainable (froozen weights)
h = x @ W
h += x @ (W_A @ W_B) * alpha # use scaled LoRA weights
return hHence the whole idea behind LoRA is to somehow represent the weight matrix as the composition of the matrix product of two weight matrices (keeping as much information of my initial matrix) and then optimize those two matrices while doing backdrop during fine-tuning. In that way, we are not only optimizing memory but also fine-tuning our model. To understand more on this topic, please check out the amazing blog post by Sebastian Raschka on Low-Rank Adaptation (LoRA) and general fine-tuning methods for LLMs.
While LoRA (Low-Rank Adapters) is an efficient method that reduces memory usage during fine-tuning, QLoRA takes this approach even further. QLoRA introduces 4-bit quantization to compress the pre-trained language model’s parameters, enabling finetuning on smaller GPUs. By using a combination of 4-bit NormalFloat (NF4) and paged optimizers, QLoRA achieves memory savings without sacrificing much performance. This innovation allows QLoRA to outperform previous models on the Vicuna benchmark and finetune large models on consumer hardware with remarkable efficiency. To know more about QLoRA check out the amazing blog post by Hugging Face
Our overall analytical pipeline with weights and bias
Back to our approach to building the analytical pipeline for text classification. We started by fine-tuning a Falcon 7B model. We used Hugging Face for using and fine-tuning our LLMs. We started with loading and building our dataset. Figure 1 shows what our dataset looks like. It has a column called narrative (which contained our text) and another column named product which contained our label.
Dataset construction
As we are dealing with a decoder-style language model, our dataset should not look like a traditional supervised dataset (containing features and labels). We mimic a classification task as a language completion task. Intuitively language modeling is just predicting the next token given the previous. Hence our prompt was constructed in a way that it predicts the next token given the whole customer complaint. Where the expected next set of tokens will be our class labels. Here is what is prompt looked like.

Here the text marked in green is our actual input text, the yellow is our starting text, and from ### Assistant is what our language model is expected to predict. Markers like ###System, ###Assistant, <|system prompt>| etc., are used during the training or fine-tuning of language models to help guide the model’s behavior and generate appropriate responses in specific contexts. These markers act as instructions or cues for the model to follow a particular format or provide certain types of responses when it encounters them in the input text.
So for the training dataset, we cast all the records into this format shown in Figure 1. For the validation, we cast the data on similar lines but just provided the ###Humans: section only, since the model will be predicting the problem code when inferencing. Here is a glimpse of our prompt during the evaluation.

Below is a sample code that shows how we can cast customers’ text into our required format. You can find our all the code used in our pipeline in this GitHub repository.
def format_text(
self,
row,
additional_prompt: Optional[str] = None,
test: Optional[bool] = None,
) -> str:
feature_row = row[self.feature]
label_row = row[self.label]
additional_prompt = "" if additional_prompt is None else additional_prompt + "\n"
if not test:
format_text = (
additional_prompt
+ f"### Human: This consumer complaint: {feature_row} is classified into category: "
+ f"### Assistant: {label_row}"
)
else:
format_text = (
additional_prompt
+ f"### Human: This consumer complaint: {feature_row} is classified into category:"
)
return format_textOnce formatting is done, then we saved our dataset in the form of JSON where each blob in JSON was like this
# if train
{
'text': '### Human .... ### Assistant ...'
}
# validation and test
{
'text': '### Human ....',
'label': '<label>'
}Once saved then we used the Hugging Face datasets library to load those JSON into the Hugging Face dataset format.
Fine Tuning pipeline
After the dataset creation process was completed, we loaded our model using the Hugging Face transformers library. As these models are causal language models, so we used AutoModelForCausalLM to load the model in 4-bit quantization. All the quantization part is been handled by BitsAndBytes the library. Here is a sample code.
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig, TrainingArguments)
model_id = "tiiuae/falcon-7b"
# load the essential configurations for quantization
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# load the model
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
quantization_config=quantization_config,
trust_remote_code=True,
)To make our experiments easier to execute and flex, as a best practice, we structured our pipeline into parameterized code functions using Python classes. We abstracted out the fine-tuning and the inference pipeline of hugging faces with our class named SimpleFineTuner and SimpleInference which met our task-specific needs.
Further, we also created our dataset class called FalconDataset which helped us to easily load different variants of the dataset, save them into JSON and load it into hugging face format. More of the code can be found here in this GitHub repository.
And after doing that our overall code squeezed into a few lines shown.
# load all the libraries
import os
import json
import wandb
import warnings
import pandas as pd
from src.finetune import SimpleFineTuner
from src.inference import SimpleInference
from src.dataset import FalconFineTuningDataset
# load the csv
PATH = os.path.join(os.getcwd(), os.pardir, os.pardir, 'Data')
csv_path = os.path.join(PATH, 'complaints_processed.csv')
# Preprocess the data and create the dataset
test_size = 150
data = pd.read_csv(csv_path)
data['product'] = data['product'].str.replace('_', ' ')
train_df, test_df = data.iloc[:-test_size], data.iloc[-test_size:]
dataset = FalconFineTuningDataset(
train_df= train_df,
test_df = test_df,
feature = 'narrative',
label = 'product'
).get_hf_dataset(
format_style=1,
json_folder_path=PATH,
validation_size=10000,
shuffle=True,
seed=42
)
# get the train, validation and test dataset
train_dataset = dataset['train_dataset']
eval_dataset = dataset['eval_dataset']
test_dataset = dataset['test_dataset']
# start writing all the necessary configurations
# for the model and load the model
model_id = "tiiuae/falcon-7b"
# load the PEFT (Parameter Efficient Fine Tuning) config
# this includes what will the size of r for our LoRA weights
# scalar value alpha, and where to apply LoRA (target modules)
peft_config_dict = {
'r': 64,
'lora_alpha' : 16,
'lora_dropout' : 0.1,
'bias': 'none',
'task_type': 'CAUSAL_LM',
'target_modules': [
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h"
],
}
# define the training arguments as json
# tip: set model's output directory inside where all the code is
train_args = {
"output_dir": "./falcon_7b_output",
"per_device_train_batch_size": 4,
"gradient_accumulation_steps": 4,
"optim": "paged_adamw_32bit",
"save_steps": 10,
"save_total_limit":5,
"logging_steps": 10,
"learning_rate": 2e-4,
"max_grad_norm": 0.3,
"max_steps": 250, # epochs
"warmup_ratio": 0.03,
"lr_scheduler_type": "constant",
"report_to": "wandb",
'run_name': "test-run-falcon7b-pretrained"
}
# make the dataset config dict
dataset_config_dict = {
'train_dataset': train_dataset,
'eval_dataset' : eval_dataset,
'dataset_text_field': 'text',
'max_seq_length': 512,
}
# instantiate our fine tuning pipeline
finetuner = SimpleFineTuner(wandb_project_name, model_id)
model, tokenizer = finetuner.load_base_model()
tokenizer.pad_token = tokenizer.eos_token
# instantiate the hugging face trainer.
# we used TRL (Transformer Reinforcement Learning) which is a wrapper around
# hugging face Trainer class. (We did not used Reinforcement Learning)
# for fine tuning, just supervised fine tuning
# more on TRL: https://huggingface.co/docs/trl/index
trainer = finetuner.load_trl_trainer(
model,
tokenizer, peft_config_dict, train_args, dataset_config_dict
)
# train the model
trainer.train()
# evaluate the model
trainer.evaluate()The best part, now using this I can now run multiple experiments with multiple configurations and variations in model, dataset, etc. Also, another awesome thing about all these optimizations is that we can also fine-tune this model using a consumer GPU (Google Colab). All the analyses related to training and the model’s performance in training will be shared in the next blog.
Validation and testing pipeline
For any organization incorporating LLMs into their systems, it is very important to evaluate the models on these three basic terms (there can be more)
- Performance of the model (like how well the generated responses are)
- Performance of the model in terms of speed
- Testing the model on reliability and robustness.
We started by evaluating all three. Now as it is a text completion model and we are using it for mimicking a classification task, hence the output we will get will always be a text. There are three possible cases.
- The generated text will not contain the expected text labels and will only contain random texts (large variance).
- The generated text will only contain expected labels (no variance)
- The generated text will contain our expected labels along with some extended text (moderate variance).
Since we can not define a hard and fast rule-based metric like accuracy for evaluating LLMs for classification, we came up with a metric called loose accuracy. The algorithm is simple, a generated text and labels are the same if the label contains inside the generated text. And accordingly, we tried to quantify our model’s performance. The performance of our initial model was 66 % in our test set. However, we improved it to a huge extent with more iterations. More on our second blog, so stay tuned.
Loading a fine-tuned model
Upon completing the fine-tuning process with 4-bit quantization and saving all the PEFT weights, I noticed an issue while attempting to upload our model weights in Hugging Face Hub, as this feature was not yet implemented. Additionally, pasting the model weight’s directory (falcon_7b_output) would lead to an error. To resolve this, ensure that you are located outside the folder containing the fine-tuned PEFT weights. Assuming you have executed the same code, you will find multiple model checkpoints within the weights folder. Below is a glimpse of the sample folder structure.
falcon_7b_output/
├── checkpoint-48
│ ├── README.md
│ ├── adapter_config.json
│ ├── adapter_model.bin
├── checkpoint-52
│ ├── README.md
│ ├── adapter_config.json
│ ├── Remember, how we define a model id in Hugging Face, tiiuae/falcon-7b , so the very first time, Hugging Face downloads this from their model repository, and the next time, it will load inside .cache/hugging-face your local. Hence the format for loading the PEFT weights, in this case, will be falcon_7b_output/checkpoint-48 . Hugging Face now will look at whether a relative directory is present there or not. And hence will load the model successfully.
Here is what the inference code looks like for that.
model_id = "tiiuae/falcon-7b"
adapter_id = 'falcon_7b_output/checkpoint-48'
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# load the actual foundation model
model = AutoModelForCausalLM.from_pretrained(
model_id,
return_dict=True,
device_map='auto',
trust_remote_code = True,
output_attentions=True,
quantization_config = quantization_config # may be this can be an arg
)
# load the peft weights and attach it to the base
model = PeftModel.from_pretrained(model, adapter_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)And now you can do inferencing or validation on your fine-tuned model.
Orchestrating our Experimentation pipeline with Weights and Bias
We had a lot of experiments to do. And managing experiments in lots of notebooks was hard. There were different variants of models, datasets, and even prompts. And hence writing the same code but with small changes for all those variations and keeping track of them was hard. And hence we thought to integrate Weights and Bias in our pipeline.
For those who do not know Weights and Bias, Weights, and Bias (W&B) is a machine learning platform that provides tools for experiment tracking, model visualization, and collaboration, enabling data scientists and researchers to better understand and optimize their models’ performance through easy-to-use interfaces and integrations.
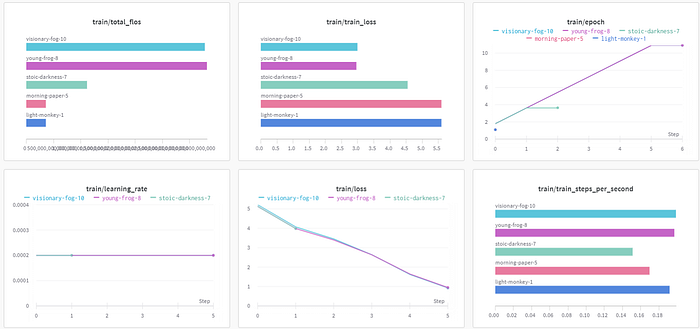
We used weights and biases to track our training procedure. This helps to see how the model is getting fine-tuned by reviewing the loss. Also, we can compare different models all at once, and their performance gets logged in one single dashboard like this
It does not end here, Weights and Bias helped us the most during the time of inference. We integrated Weights and Bias in our inference pipeline to track the comparison of our model’s generated output with the class label for the following text. Below is a sample snapshot for the same.
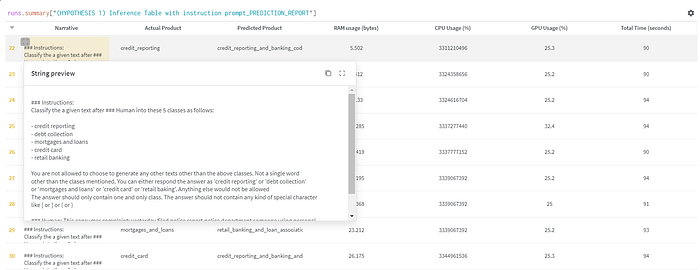
This helped us to analyze the texts for which the model was not performing well and we got lots of amazing insights like this. More on our next blog.
Conclusion
In this blog, we have learned about how we can effectively fine-tune our large language model for domain-specific tasks. Here we used it for classification. We also discovered some of the best practices, like how we can create scripts and organize our whole experimentation procedure with tracking tools like Weights and Bias. In the next blog, we will show you some insights into the performance of the model and how it improved with different combinations in terms of dataset, model, prompts, and how much each component contributes towards the model’s refined performance. Stay tuned.
